
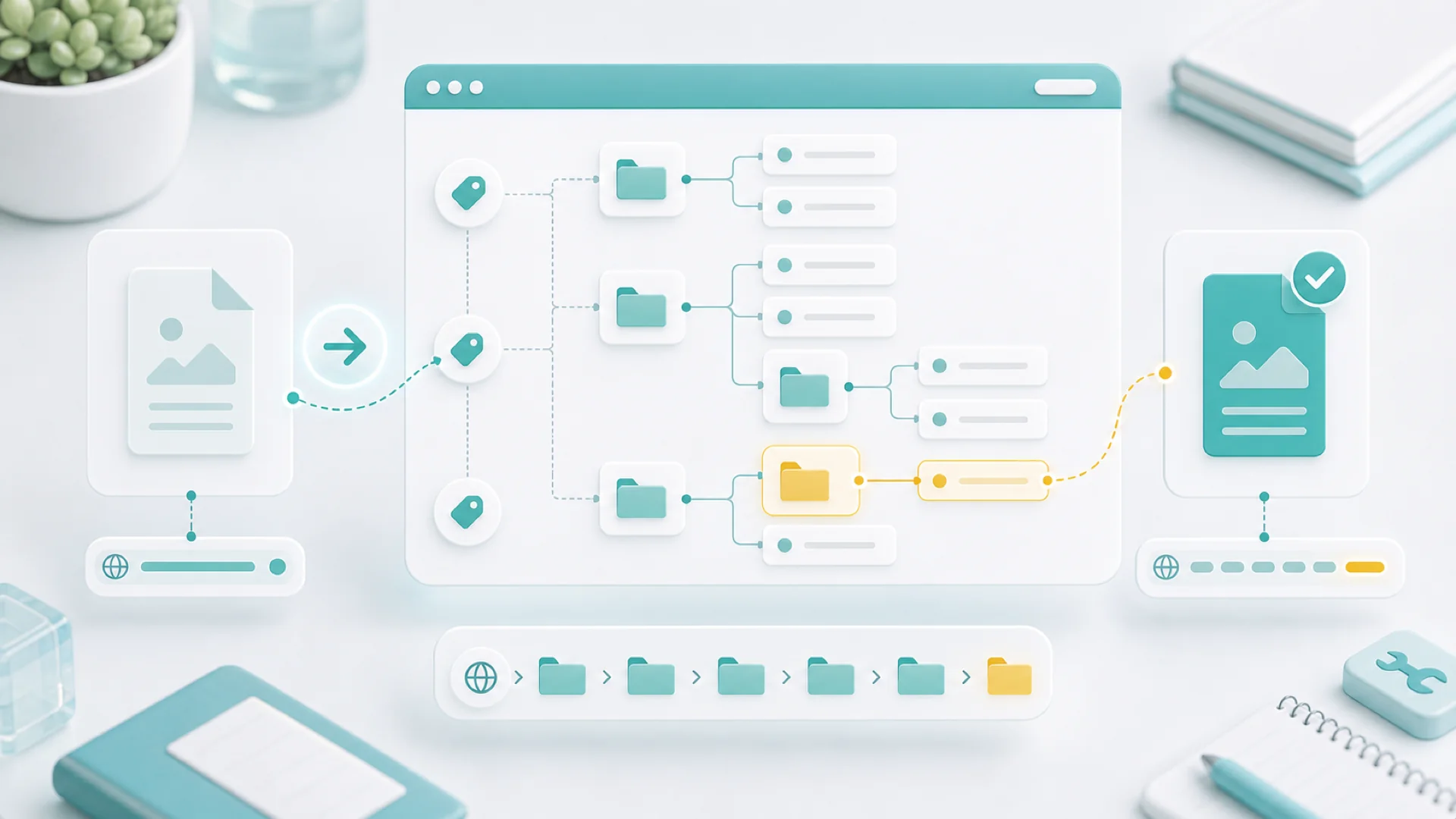
Our CMS routes nested content — /help/customers/crm-setup/import-or-add-contacts/, /blog/engineering/this-post/ — without a routing table, a docs platform, or folder-based pages. The mechanism: designated root tags own URL trees, an article's path is derived from the deepest tag it carries under that root, and old flat URLs redirect themselves to the canonical nested path. This post is about why that design, and where it bites.
Every CMS eventually faces the same request: "can the help center live at /help/billing/refunds/ instead of a flat pile of posts?" The standard answers are all expensive — bolt on a separate documentation platform and fork your content pipeline, or invent folder-based pages and lose everything the post machinery gives you (authors, scheduling, feeds, search). We wanted nested URLs without a second content system. The piece we bent was the one already lying around: tags.
Tags are flat. Content trees aren't.
Tags are the most underrated primitive in content systems: every post already carries them, every theme already renders them, every API already filters by them. Their one limitation is flatness — a tag is a label, not a place. So we gave tags two optional properties they were missing: a parent, making hierarchy expressible, and — for a chosen few — ownership of a URL tree.
That second property is deliberately opt-in. A site-level setting lists which root tags own permalink trees:
{
"enabled": true,
"root_slugs": ["help", "blog"],
"strip_root_prefix": true
}Everything not under those roots behaves exactly as before — flat slugs, ordinary tag pages. The feature changes nothing for the ninety percent of content that never asked for hierarchy, which is most of what made it shippable: no migration, no flag day, no retraining anyone.
The deepest-tag rule
An article's nested path is derived, not stored. The resolver walks the tags a post carries, finds the ones that belong to an enabled root tree, and takes the deepest — then builds the path from that tag's lineage. A post tagged help → customers → crm-setup renders at /help/customers/crm-setup/<slug>/. This post carries blog → engineering, so it lives where your address bar says it does.
Deriving rather than storing buys the property that matters most at scale: reorganization is retagging. Move a child tag under a different parent and every post beneath it moves with it — no per-post migration, no path fields drifting out of sync with taxonomy. The category pages come along for free too, since a tag page at /blog/engineering/ is just the tag rendered at its lineage path. One detail earns its keep in the config above: strip_root_prefix. Child tag slugs are globally unique in the CMS, so ours are prefixed (blog-engineering); stripping the root prefix at path-build time keeps URLs clean while letting slugs stay collision-free.
The slug is identity. The path is presentation.
Once those are separate concerns, reorganizing content stops being a migration.
Redirects you never have to write
Separating identity from presentation pays off again at the router. A post's slug is unique site-wide regardless of where its path currently lives — so when a request arrives at the old flat address, the router recognizes the slug, computes today's canonical path, and answers with a 301. When we moved three existing posts into the blog tree, their old root-level URLs started redirecting to the nested ones the moment the tags changed. Nobody wrote a redirect rule; there is no redirect table to rot. The same holds for future reorganizations: retag, and inbound links keep working.
One lineage, three features
The lineage that builds the URL turns out to be exactly the data navigation needs, so templates receive it as a content tree context: the breadcrumb is the lineage rendered as links; the section sidebar is "other posts under my deepest tag"; previous/next is position among those siblings. The help center's docs layout and this blog's three-column reading view are both consumers of that one context — which is the quiet architectural win. URL structure, navigation, and category pages are one mechanism, so they cannot disagree with each other. There is no state where the breadcrumb says one place and the address bar says another.
Where it bites
- One post, two trees. A post tagged into both
helpandblogtrees has two defensible paths. The resolver picks deterministically, but the honest answer is editorial: don't do that. Cross-reference with a link instead — our own publishing rules forbid a post carrying two tree memberships. - Renames are public events. Renaming a category tag's slug changes every URL beneath it. Slug-level redirects soften it for articles, but category pages at the old path 404 — so category renames follow a checklist (display name first, slug only with intent), not a whim.
- Empty categories must hide. A freshly created subtree with no published posts would render as a skeleton of empty index pages. The visibility rule — a tag surfaces only when its subtree contains published content — keeps half-built taxonomies invisible until they're real.
- Depth is a taste decision the system won't make for you. Nothing technical stops five-level nesting. We keep the blog to exactly one level (
/blog/<category>/) and the help center to two, because every level is a promise to maintain it.
What we didn't build
Three rejected roads, for the record. A routing-table DSL (regex routes mapping paths to collections) — flexible, and a config file that becomes load-bearing folklore within a year. A separate docs platform — instant feature parity questions for search, authors, scheduling, and the slow content fork that follows. And storing paths on posts — simplest on day one, and the source of every "the page moved but the old path still renders" bug we've ever had elsewhere. Deriving paths from the tag graph was the version with the fewest moving parts that could disagree.
Key takeaways
- Extend the primitive you have: tags with parents and opt-in URL ownership, not a second content system.
- Derive, don't store: deepest-tag lineage builds the path, so reorganizing is retagging.
- Slug = identity, path = presentation — which makes redirects automatic and permanent.
- One lineage powers URL, breadcrumb, sidebar, and prev/next — features that share a source can't contradict.
- The hard parts are editorial: tree membership, rename discipline, and depth restraint.
Frequently asked questions
Why tags instead of a folder or page-tree model?
Because posts already flow through tags — feeds, search, related-content, theming, APIs. A folder model would have needed all of that re-implemented for a second content type. Bending the existing primitive kept one pipeline for everything from a marketing blog to a 220-article help center.
What happens if a post carries only the root tag?
The root is its deepest tree tag, so it renders directly under the root path. That's legitimate for genuinely uncategorized content, but our own convention requires a category tag — a tree where most things live at the root isn't a tree.
How do themes adapt between nested and flat content?
The template checks whether the post arrived with a content tree context. Present means the nested reading layout — breadcrumb, section nav, on-this-page rail; absent means the classic post layout. One template, branching on data rather than on hardcoded path checks.
Does the nesting depth hurt SEO?
Search engines care about content and links far more than slash count, and shallow trees with meaningful segments tend to help comprehension — the path describes the content. What would hurt is churn, which is exactly what the automatic redirects and rename discipline exist to prevent.
Could one site run many trees — docs, blog, a resource library?
Yes — the root list is just configuration, and each tree is independent: its own hierarchy, its own depth conventions, its own landing page. The marginal cost of a new tree is creating a root tag and deciding, editorially, what belongs in it. That last part is the real work.
The pattern generalizes beyond CMSs: when a feature request sounds like "we need a second system," look first for the existing primitive that's one property short. Ours was a label that needed a parent. The user-facing version of all this — enabling trees, fixing category 404s, renaming safely — lives in the help center; this was the reasoning underneath.
Helpful guides
For the help-center operations behind nested URLs, redirects, and category changes, use these guides:


